library(conflicted)
library(tidyverse)
conflict_prefer_all("dplyr", quiet = TRUE)
conflicts_prefer(lubridate::as_date)
library(rvest)
library(scales)
library(SPARQL)
library(clock)
conflicts_prefer(clock::date_format)
library(glue)
library(janitor)
library(infer)
library(tsibble)
library(ggfx)
library(paletteer)
library(ggfoundry)
library(usedthese)
conflict_scout()Bootstraps & Bandings
R
statistical inference
regex
special effects
web scraping
Decades-old residential property bands and inference using a sample of those recently sold

Are the residential property bands of 3 decades ago becoming less so? Would a sample of those recently-sold reveal band convergence? And what may be inferred about those not sampled?
Over the years, urban properties have been added to and divided up. And two streets of equal attractiveness, and with equivalently-banded properties, may have diverged as neighbourhoods evolved.
Whilst properties can and do move to higher or lower bands following alteration, would a sample of those recently-sold reveal band convergence after so long? And what may be inferred about the wider housing stock?
Setting the theme and colour palette for all graphics (with a little help from the ggfx package).
theme_set(theme_bw())
pal_name <- "RColorBrewer::RdYlBu"
pal <- paletteer_d(pal_name, 7)
display_palette(pal, pal_name)
Property band and price-paid data are separately sourced. The free-form street address is the only way to bring the two together. The structure, content and even spelling of the address sometimes differ, for example: “FLAT C, 22 SOME STREET, SOME AREA, SW10 1AA” in one may be “22C 2ND FLR, HOUSE NAME, SOME STREET SW10 1AA” in the other.
So, a little string manipulation is needed to create a common key. And reusable patterns will enable a consistent application to both.
Tip
Hover over the numbered code annotation symbols for REGEX explanations.
remove_pattern <-
str_c(
", London, SW10 .+$",
"FLAT ",
"APARTMENT ",
"CHELSEA HARBOUR",
"(?<=COURT|SANDHILLS| HOUSE|WALK|ESTATE|ROW).*",
"[,'\\.]",
"(?<= )AT ",
"(?<=VINT)N",
"(?<=FARRIER)S",
"(1ST|2ND|3RD|4TH|5TH|6TH) FLR ",
"FLR (1ST|2ND|3RD|4TH|5TH|6TH) ",
" ?- ?[0-9]{1,3}",
sep = "|"
)
swizzle_from <- "^([0-9]{1,3})([A-Z])(?= .*)"
swizzle_to <- "\\2 \\1"- 1
- Looks for strings that end with 1 or more characters following the London postcode district of “SW10”.
- 2
-
Uses a positive lookbehind to find anything, for example, following the word
COURTorWALK(since the postcode is stored in a separate variable and already isolates the road, so the road name is redundant). - 3
-
Finds any occurrences of
1ST FLR,FLR 1STetc. - 4
-
Uses capture groups to temporarily memorise a number (capture group 1) followed by a letter (capture group 2), then swap them around. This is because a flat number may be
C22in one dataset and22Cin the other.
Council Tax band data are available for non-commercial use1.
url1 <-
str_c(
"https://www.tax.service.gov.uk/",
"check-council-tax-band/",
"search-council-tax-advanced?",
"postcode=Fkvms5WVQum-uX3L00_pcA&",
"filters.councilTaxBands="
)
url2 <- "&filters.propertyUse=N&postcode=Fkvms5WVQum-uX3L00_pcA&page="
url3 <- "&filters.bandStatus=Current"
index <- crossing(band = LETTERS[1:8], page = seq(0, 120, 1))
band_df <- map2(index$band, index$page, possibly(\(i, j) {
str_c(url1, i, url2, j, url3) |>
read_html() |>
html_element("#search-results-table") |>
html_table(convert = FALSE)
}, otherwise = NA_character_)) |>
list_rbind()band_df2 <-
band_df |>
clean_names() |>
mutate(postcode = str_extract(address, "SW10 .+$"),
raw_band_address = str_remove(address, ", London, SW10 .+$"),
address = str_remove_all(address, remove_pattern),
address = str_replace(address, swizzle_from, swizzle_to),
address = str_squish(address)
)House price-paid data are similarly available for non-commercial use2.
endpoint <- "https://landregistry.data.gov.uk/landregistry/query"
query <- '
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX text: <http://jena.apache.org/text#>
PREFIX ppd: <http://landregistry.data.gov.uk/def/ppi/>
PREFIX lrcommon: <http://landregistry.data.gov.uk/def/common/>
SELECT ?ppd_propertyAddress ?ppd_transactionCategory ?ppd_transactionDate ?ppd_pricePaid ?ppd_estateType ?ppd_propertyAddressCounty ?ppd_propertyAddressDistrict ?ppd_propertyAddressLocality ?ppd_propertyAddressPaon ?ppd_propertyAddressPostcode ?ppd_propertyAddressSaon ?ppd_propertyAddressStreet ?ppd_propertyAddressTown ?ppd_propertyType ?ppd_recordStatus
WHERE
{ { ?ppd_propertyAddress
text:query ( lrcommon:postcode "( SW10 )" 3000000 ) .
?item ppd:propertyAddress ?ppd_propertyAddress ;
ppd:transactionCategory ppd:standardPricePaidTransaction ;
ppd:transactionDate ?ppd_transactionDate ;
ppd:pricePaid ?ppd_pricePaid ;
FILTER ( ?ppd_transactionDate >= "2020-01-01"^^xsd:date )
}
OPTIONAL{ ?item ppd:estateType ?ppd_estateType }
OPTIONAL{ ?ppd_propertyAddress lrcommon:county ?ppd_propertyAddressCounty}
OPTIONAL{ ?ppd_propertyAddress lrcommon:district ?ppd_propertyAddressDistrict}
OPTIONAL{ ?ppd_propertyAddress lrcommon:locality ?ppd_propertyAddressLocality}
OPTIONAL{ ?ppd_propertyAddress lrcommon:paon ?ppd_propertyAddressPaon}
OPTIONAL{ ?ppd_propertyAddress lrcommon:postcode ?ppd_propertyAddressPostcode}
OPTIONAL{ ?ppd_propertyAddress lrcommon:saon ?ppd_propertyAddressSaon}
OPTIONAL{ ?ppd_propertyAddress lrcommon:street ?ppd_propertyAddressStreet}
OPTIONAL{ ?ppd_propertyAddress lrcommon:town ?ppd_propertyAddressTown}
OPTIONAL{ ?item ppd:propertyType ?ppd_propertyType }
OPTIONAL{ ?item ppd:recordStatus ?ppd_recordStatus }
BIND(ppd:standardPricePaidTransaction AS ?ppd_transactionCategory)
}'
prices_list <- SPARQL(endpoint, query)prices_df2 <-
prices_list$results |>
as_tibble() |>
clean_names() |>
rename_with(~ str_remove_all(., "ppd_|property_address_")) |>
mutate(
transaction_date = as_datetime(transaction_date) |> as_date(),
price_paid = price_paid / 1000000
) |>
filter(transaction_date < "2022-01-01") |>
mutate(
raw_price_address = str_c(str_replace_na(saon, ""),
paon, street, sep = " ") |> str_squish(),
address = str_remove_all(raw_price_address, remove_pattern),
address = str_replace(address, swizzle_from, swizzle_to)
) |>
select(
address,
raw_price_address,
postcode,
price_paid,
transaction_date,
estate_type,
property_type,
transaction_category
)Now there’s a common key to join the data.
joined_df <-
prices_df2 |>
inner_join(band_df2, by = join_by(address, postcode)) |>
relocate(raw_band_address, .after = raw_price_address) |>
arrange(postcode, address) |>
mutate(council_tax_band = factor(council_tax_band))As with previous posts Digging Deep and House Sales, I’m focusing on postcodes in the SW10 part of London.
It’s not possible to assess all SW10 properties by band since only a tiny fraction will have been sold recently. Recent sales could though be used as a sample and Bootstrap Confidence Intervals then employed to draw a wider inference.
“Pulling yourself up by your bootstraps” originally meant doing something absurd. Later it came to mean succeeding with only what you have at your disposal. Hence only the sample will be used as a surrogate for the true population by making repeated random draws from it (with replacement).
A key assumption is that the sample is representative of the true population.
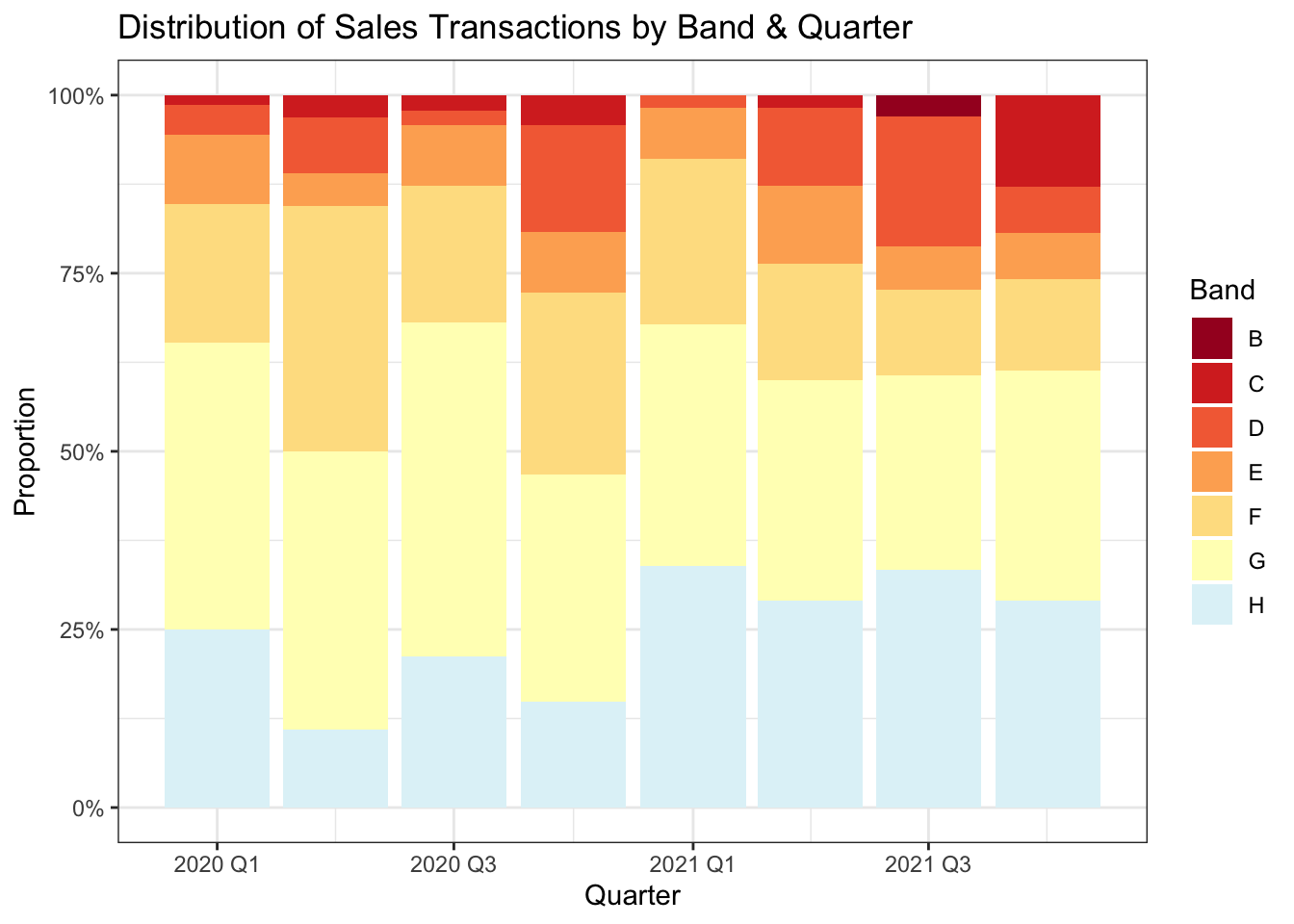
Even though only recent sales transactions have been selected, a small movement in market prices will have occurred. So ensuring the bands are reasonably well distributed over the period is worthwhile.
joined_df |>
select(transaction_date, price_paid, council_tax_band) |>
mutate(yearquarter = yearquarter(transaction_date)) |>
count(yearquarter, council_tax_band) |>
ggplot(aes(yearquarter, n, fill = council_tax_band)) +
geom_col(position = position_fill()) +
scale_x_yearquarter() +
scale_y_continuous(labels = label_percent(1)) +
scale_fill_manual(values = pal[c(1:7)]) +
labs(
title = "Distribution of Sales Transactions by Band & Quarter",
x = "Quarter", y = "Proportion", fill = "Band"
)
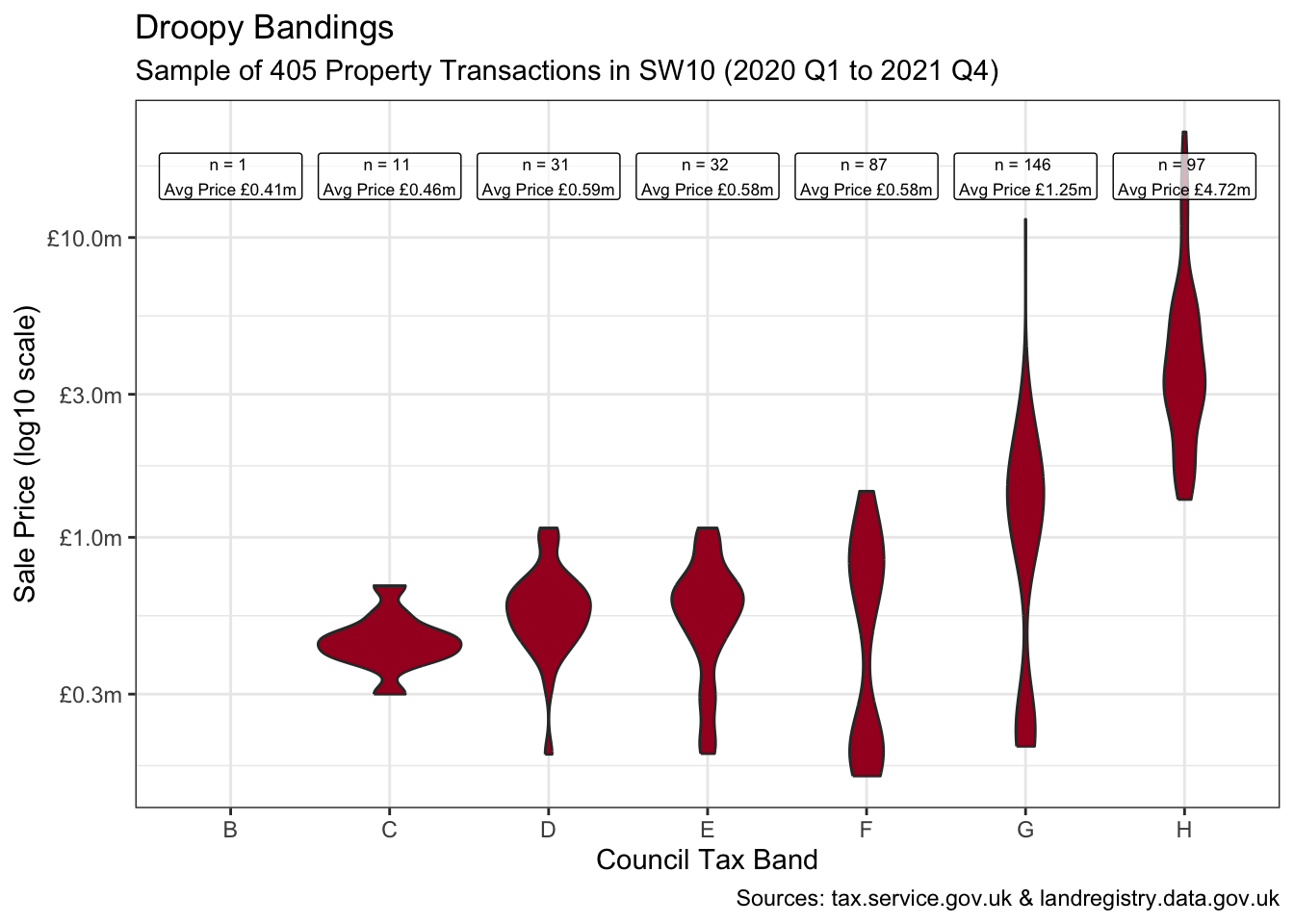
A violin plot of the property values by band shows some bimodal distribution and oddly shows bands E & F with lower mean prices than band D. This is worth closer inspection to ensure the sample is representative.
labels <- joined_df |>
summarise(n = n(), mean_price = mean(price_paid),
.by = council_tax_band)
transactions <-
joined_df |>
count() |>
pull()
from <- joined_df |>
summarise(min(transaction_date) |> yearquarter()) |>
pull()
to <- joined_df |>
summarise(max(transaction_date) |> yearquarter()) |>
pull()
joined_df |>
ggplot(aes(council_tax_band, price_paid)) +
geom_violin(fill = pal[1]) +
geom_label(aes(label = glue(
"n = {n} \nAvg Price ",
"{label_currency(prefix = '£', suffix = 'm', accuracy = 0.01)(mean_price)}"
), y = 16),
data = labels, size = 2.3, alpha = 0.7, fill = "white"
) +
scale_y_log10(labels = label_currency(
prefix = "£",
suffix = "m", accuracy = 0.1
)) +
labs(
title = "Droopy Bandings",
subtitle = glue(
"Sample of {transactions} Property ",
"Transactions in SW10 ({from} to {to})"
),
x = "Council Tax Band", y = "Sale Price (log10 scale)",
caption = "Sources: tax.service.gov.uk & landregistry.data.gov.uk"
)
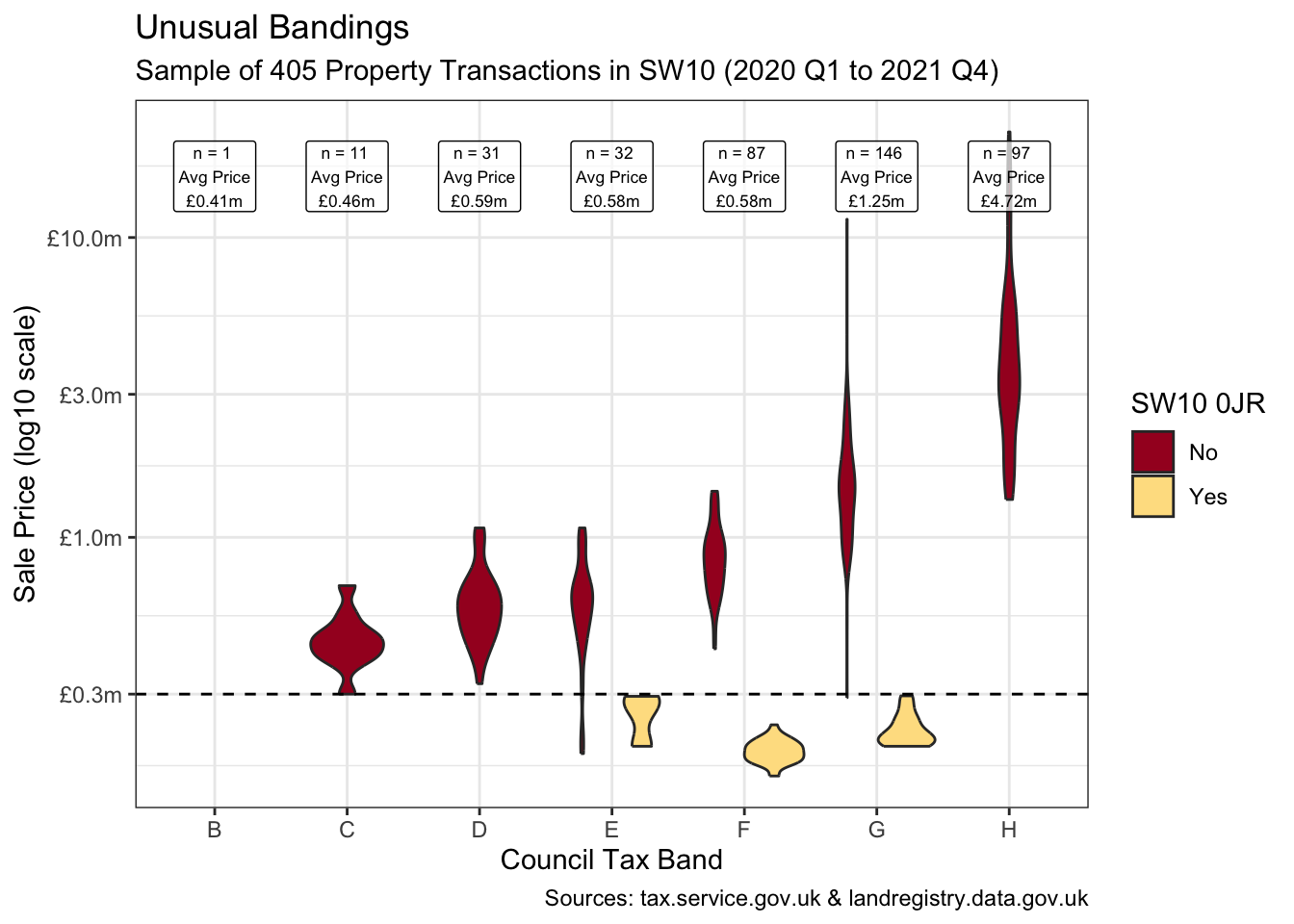
joined_df2 <- joined_df |>
mutate(`SW10 0JR` = if_else(postcode == "SW10 0JR", "Yes", "No"))It turns out that the unusual transactions below £0.3m are almost entirely from one postcode as shown below when isolating “SW10 0JR”. This appears to be a single large new development with all sub-units sold in 2020.
These specific transactions feel somewhat unusual at these banding levels. And irrespective of their accuracy, a sample of 173 postcodes heavily dominated by the transactions of just one would not be representative of the true population.
joined_df2 |>
ggplot(aes(council_tax_band, price_paid, fill = `SW10 0JR`)) +
geom_violin() +
geom_label(aes(label = glue(
"n = {n} \nAvg Price\n",
"{label_currency(prefix = '£', suffix = 'm', accuracy = 0.01)(mean_price)}"
), y = 16),
data = labels, size = 2.3, alpha = 0.7, fill = "white"
) +
geom_hline(yintercept = 0.3, linetype = "dashed") +
scale_y_log10(labels = label_currency(
prefix = "£",
suffix = "m", accuracy = 0.1
)) +
scale_fill_manual(values = pal[c(1, 5)]) +
labs(
title = "Unusual Bandings",
subtitle = glue(
"Sample of {transactions} Property ",
"Transactions in SW10 ({from} to {to})"
),
x = "Council Tax Band", y = "Sale Price (log10 scale)",
caption = "Sources: tax.service.gov.uk & landregistry.data.gov.uk"
)
joined_df2 |>
count(postcode, sort = TRUE) |>
slice_head(n = 10)| postcode | n |
|---|---|
| SW10 0JR | 79 |
| SW10 0HQ | 10 |
| SW10 9JP | 8 |
| SW10 0AA | 7 |
| SW10 0HG | 7 |
| SW10 0DD | 6 |
| SW10 9AD | 6 |
| SW10 0BF | 5 |
| SW10 0UY | 5 |
| SW10 9BT | 5 |
So, I’ll remove this postcode.
joined_df3 <- joined_df |>
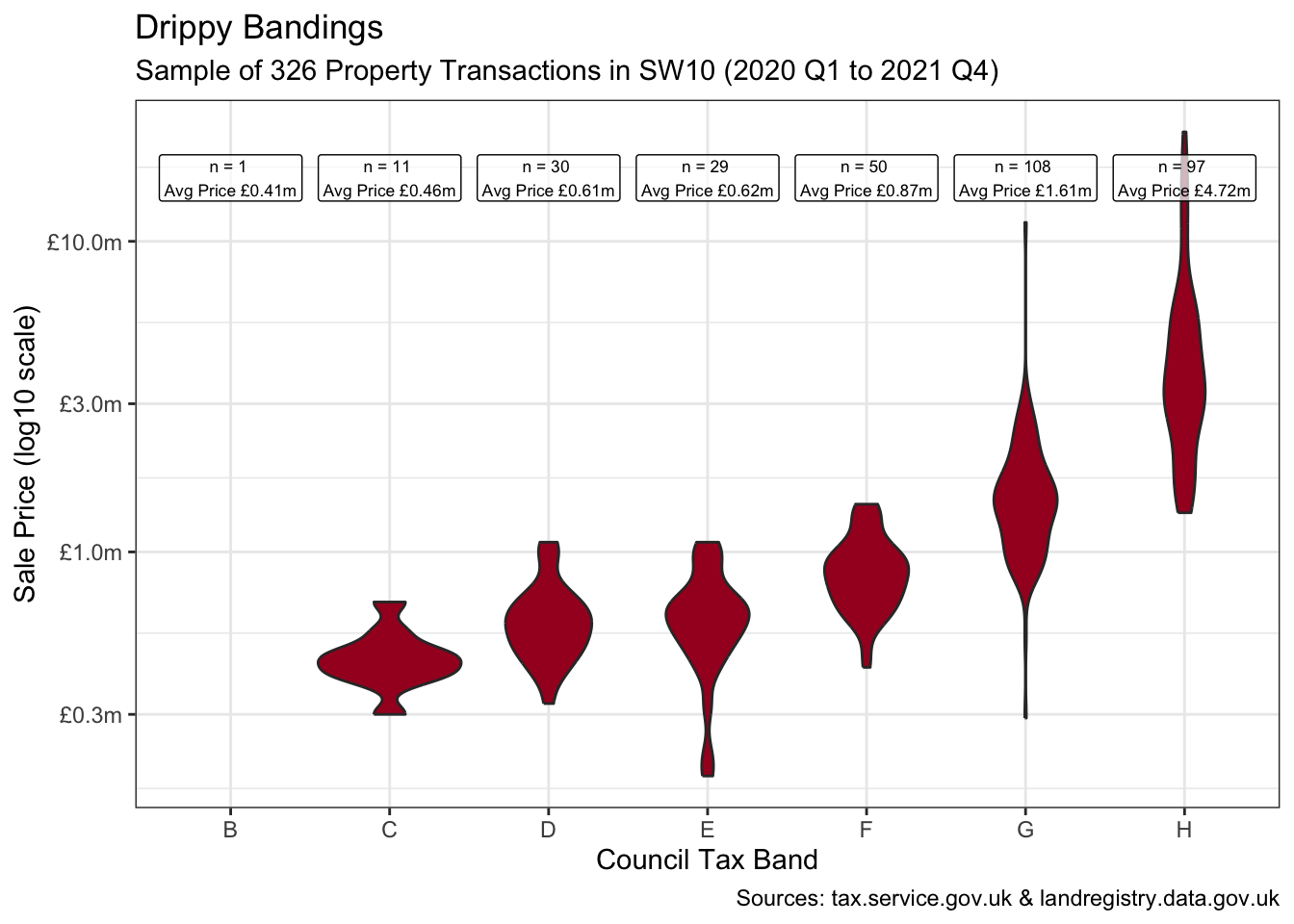
filter(postcode != "SW10 0JR")This now feels like a representative sample of 326 property transactions. And broadly-speaking the plot shows a progression in average property values as we step through the bands. There is though substantial convergence between some, with the “drippy” band E still looking almost indistinguishable from band D.
labels <- joined_df3 |>
summarise(n = n(), mean_price = mean(price_paid),
.by = council_tax_band)
transactions <-
joined_df3 |>
count() |>
pull()
joined_df3 |>
ggplot(aes(council_tax_band, price_paid)) +
geom_violin(fill = pal[1]) +
geom_label(aes(label = glue(
"n = {n} \nAvg Price ",
"{label_currency(prefix = '£', suffix = 'm', accuracy = 0.01)(mean_price)}"
), y = 16),
data = labels, size = 2.3, alpha = 0.7, fill = "white"
) +
scale_y_log10(labels = label_currency(prefix = "£",
suffix = "m", accuracy = 0.1)) +
labs(
title = "Drippy Bandings",
subtitle = glue(
"Sample of {transactions} Property ",
"Transactions in SW10 ({from} to {to})"
),
x = "Council Tax Band", y = "Sale Price (log10 scale)",
caption = "Sources: tax.service.gov.uk & landregistry.data.gov.uk"
)
Some band E examples:
joined_df3 |>
filter(council_tax_band == "E", price_paid >= 0.6) |>
select(
address = raw_price_address,
postcode,
transaction_date,
price_paid,
tax_band = council_tax_band,
estate_type,
property_type
) |>
mutate(across(ends_with("type"), \(x) str_remove_all(x, "^.*mon/|>$"))) |>
select(-address)- 1
- Removes the URL wrapped around the estate and property types, i.e. “<http://landregistry.data.gov.uk/def/common/” before and “>” after the type.
| postcode | transaction_date | price_paid | tax_band | estate_type | property_type |
|---|---|---|---|---|---|
| SW10 0AN | 2020-03-18 | 0.83000 | E | leasehold | flat-maisonette |
| SW10 0AP | 2021-06-22 | 0.67500 | E | leasehold | flat-maisonette |
| SW10 0AW | 2021-03-29 | 0.69500 | E | leasehold | flat-maisonette |
| SW10 0AX | 2020-02-21 | 0.65000 | E | leasehold | flat-maisonette |
| SW10 0BG | 2021-03-30 | 0.76500 | E | leasehold | flat-maisonette |
| SW10 0HP | 2021-10-12 | 0.67500 | E | leasehold | flat-maisonette |
| SW10 0LB | 2021-04-15 | 0.63000 | E | leasehold | flat-maisonette |
| SW10 0PE | 2020-03-25 | 0.68000 | E | leasehold | flat-maisonette |
| SW10 9AD | 2021-06-21 | 1.07500 | E | leasehold | flat-maisonette |
| SW10 9ED | 2020-10-29 | 0.60000 | E | leasehold | flat-maisonette |
| SW10 9JG | 2021-11-16 | 0.91500 | E | leasehold | flat-maisonette |
| SW10 9JX | 2020-09-14 | 1.00000 | E | leasehold | flat-maisonette |
| SW10 9JY | 2021-08-30 | 1.00000 | E | leasehold | flat-maisonette |
| SW10 9JY | 2020-08-06 | 0.67950 | E | leasehold | flat-maisonette |
| SW10 9PJ | 2020-12-14 | 0.68925 | E | leasehold | flat-maisonette |
Can we infer that the true population of band Es no longer exhibits any difference in mean values with respect to band D?
bands_ef <-
joined_df3 |>
filter(council_tax_band %in% c("E", "D"))
obs_stat <-
bands_ef |>
specify(price_paid ~ council_tax_band) |>
calculate(stat = "diff in means", order = c("E", "D")) |>
pull()
set.seed(2)
boot_dist <-
bands_ef |>
specify(price_paid ~ council_tax_band) |>
generate(reps = 2000, type = "bootstrap") |>
calculate(stat = "diff in means", order = c("E", "D"))
perc_ci <- get_ci(boot_dist)
lower <- label_currency(prefix = "£", suffix = "m", accuracy = 0.01)(perc_ci |>
pull(lower_ci))
upper <- label_currency(prefix = "£", suffix = "m", accuracy = 0.01)(perc_ci |>
pull(upper_ci))
boot_dist |>
visualise() +
shade_confidence_interval(
endpoints = perc_ci,
color = pal[6], fill = pal[3]
) +
geom_vline(xintercept = obs_stat, linetype = "dashed", colour = "white") +
annotate("label",
x = -0.12, y = 350, size = 3,
label = glue(
"Observed Difference\nBetween Bands D & E is ",
"{label_currency(prefix = '£', suffix = 'm', accuracy = 0.01)(obs_stat)}"
)
) +
scale_x_continuous(labels = label_currency(
prefix = "£",
suffix = "m", accuracy = 0.1
)) +
labs(
subtitle = glue(
"95% Confident the Difference ",
"in Mean Prices Between Bands D & E is {lower} to {upper}"
),
x = "Difference in Means", y = "Count",
caption = "Sources: tax.service.gov.uk & landregistry.data.gov.uk"
)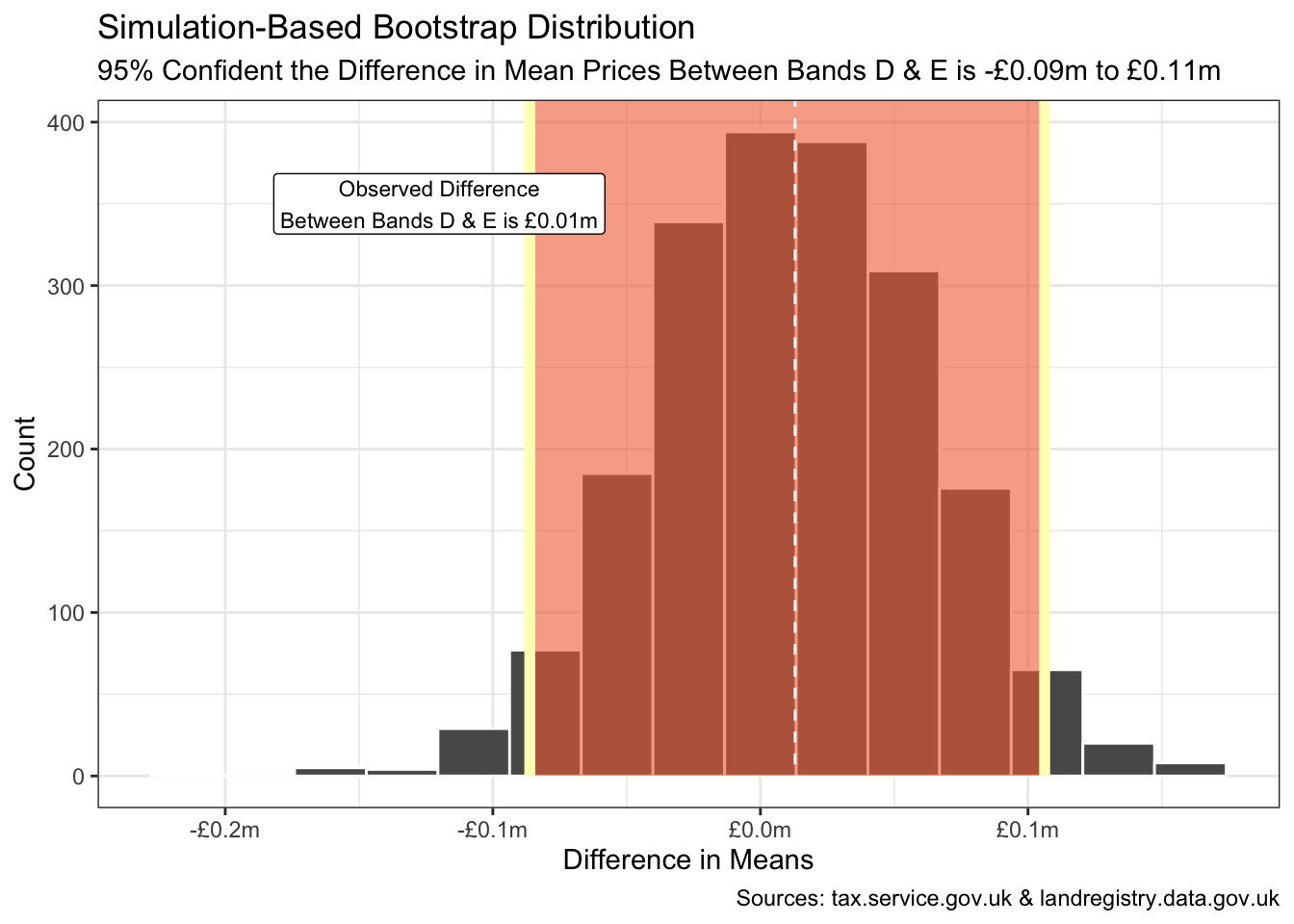
Bootstrapping with a 95% confidence interval suggests the true difference in mean prices between all band D and E properties in SW10 is somewhere in the range -£0.09m to £0.11m. Considerable convergence compared to 3 decades ago when the band E minimum exceeded the band D maximum.
R Toolbox
Summarising below the packages and functions used in this post enables me to separately create a toolbox visualisation summarising the usage of packages and functions across all posts.
used_here()| Package | Function |
|---|---|
| SPARQL | SPARQL[1] |
| base | c[5], factor[1], library[14], max[1], mean[2], min[1], readRDS[1], seq[1], set.seed[2] |
| conflicted | conflict_prefer_all[1], conflict_scout[1], conflicts_prefer[2] |
| dplyr | across[1], arrange[1], count[4], filter[4], if_else[1], inner_join[1], join_by[1], mutate[7], n[2], pull[7], relocate[1], rename_with[1], select[5], slice_head[1], slice_sample[1], summarise[4] |
| ggfoundry | display_palette[1] |
| ggplot2 | aes[7], annotate[1], geom_col[1], geom_hline[1], geom_label[3], geom_violin[3], geom_vline[1], ggplot[4], labs[5], position_fill[1], scale_fill_manual[2], scale_x_continuous[1], scale_y_continuous[1], scale_y_log10[3], theme_bw[1], theme_set[1] |
| glue | glue[8] |
| infer | calculate[2], generate[1], get_ci[1], shade_confidence_interval[1], specify[2], visualise[1] |
| janitor | clean_names[2] |
| lubridate | as_date[1], as_datetime[1] |
| paletteer | paletteer_d[1] |
| purrr | list_rbind[1], map2[1], possibly[1] |
| rvest | html_element[1], html_table[1] |
| scales | label_currency[10], label_percent[1] |
| stringr | str_c[4], str_extract[1], str_remove[1], str_remove_all[4], str_replace[2], str_replace_na[1], str_squish[2] |
| tibble | as_tibble[1] |
| tidyr | crossing[1] |
| tidyselect | ends_with[1] |
| tsibble | scale_x_yearquarter[1], yearquarter[3] |
| usedthese | used_here[1] |
| xml2 | read_html[1] |
Footnotes
This data is licensed under the Open Government Licence v3.0.↩︎
Contains HM Land Registry data © Crown copyright and database right 2021. This data is licensed under the Open Government Licence v3.0.↩︎