library(conflicted)
library(tidyverse)
conflict_prefer_all("dplyr", quiet = TRUE)
conflicts_prefer(lubridate::as_date)
library(clock)
conflicts_prefer(clock::date_format)
library(janitor)
library(scales)
library(glue)
library(ggfoundry)
library(paletteer)
library(usedthese)
conflict_scout()Let’s Jitter
Welcome to the tidyverse with data ingestion, cleaning and tidying. And some visualisations of sales data with a little jittering.

Welcome to the tidyverse (Wickham et al. 2019) with data ingestion, cleaning and tidying. And some visualisations of sales data with a little jittering.
This first little project uses the tidyverse collection of packages to import, explore and visualise some sales data. The UK Government’s Digital Marketplace provides a rich and varied source of public data under the Open Government Licence 1.
The marketplace was set up with an intent to break down barriers that impede Small and Medium Enterprises (SMEs) from bidding for Public Sector contracts. So, let’s see how that’s going.
theme_set(theme_bw())
pal_name <- "wesanderson::Royal1"
pal <- paletteer_d(pal_name)
display_palette(pal, pal_name)
The tidyverse framework sits at the heart of all my data science work as evidenced in my favourite things. So I’ll begin by using two of my most used tidyverse packages (readr (Wickham, Hester, and Bryan 2022) and dplyr (Wickham et al. 2022)) to import and tidy the cloud services (G-Cloud) sales data.
Wild data are often scruffy affairs. Cleaning and tidying is a necessary first step. In the case of these data, there are characters in an otherwise numeric spend column. And the date column is a mix of two formats.
url <- str_c(
"https://www.gov.uk/government/",
"uploads/system/uploads/attachment_data/",
"file/639799/g-cloud-sales-figures-july2017.csv"
)
gcloud_df <-
read_csv(url) |>
clean_names() |>
mutate(
evidenced_spend = str_remove_all(evidenced_spend, "[^0-9-]") |>
parse_number(),
spend_date = as.Date(as.numeric(return_month), origin = "1899-12-30"),
spend_date = if_else(
is.na(spend_date),
dmy(return_month),
spend_date
),
sme_status = if_else(sme_status == "SME", "SME", "Non-SME"),
sme_spend = if_else(sme_status == "SME", evidenced_spend, 0)
)Now we can summarise and visualise how the SME share has changed over time using the ggplot2 package.
share_df <- gcloud_df |>
summarise(
evidenced_spend = sum(evidenced_spend, na.rm = TRUE),
sme_spend = sum(sme_spend, na.rm = TRUE),
pct = sme_spend / evidenced_spend,
.by = spend_date
) |>
arrange(spend_date)
last_date <- gcloud_df |>
summarise(max(spend_date)) |>
pull() |>
date_format(format = "%B %d, %Y")
share_df |>
ggplot(aes(spend_date, pct)) +
geom_point(colour = pal[4]) +
geom_smooth(colour = pal[2], fill = pal[3]) +
scale_y_continuous(labels = label_percent()) +
scale_x_date(date_breaks = "years", date_labels = "%Y") +
labs(
x = NULL, y = NULL,
title = glue("SME Share of G-Cloud to {last_date}"),
subtitle = "Dots = % Monthly Sales via SMEs",
caption = "Source: GOV.UK G-Cloud Sales"
)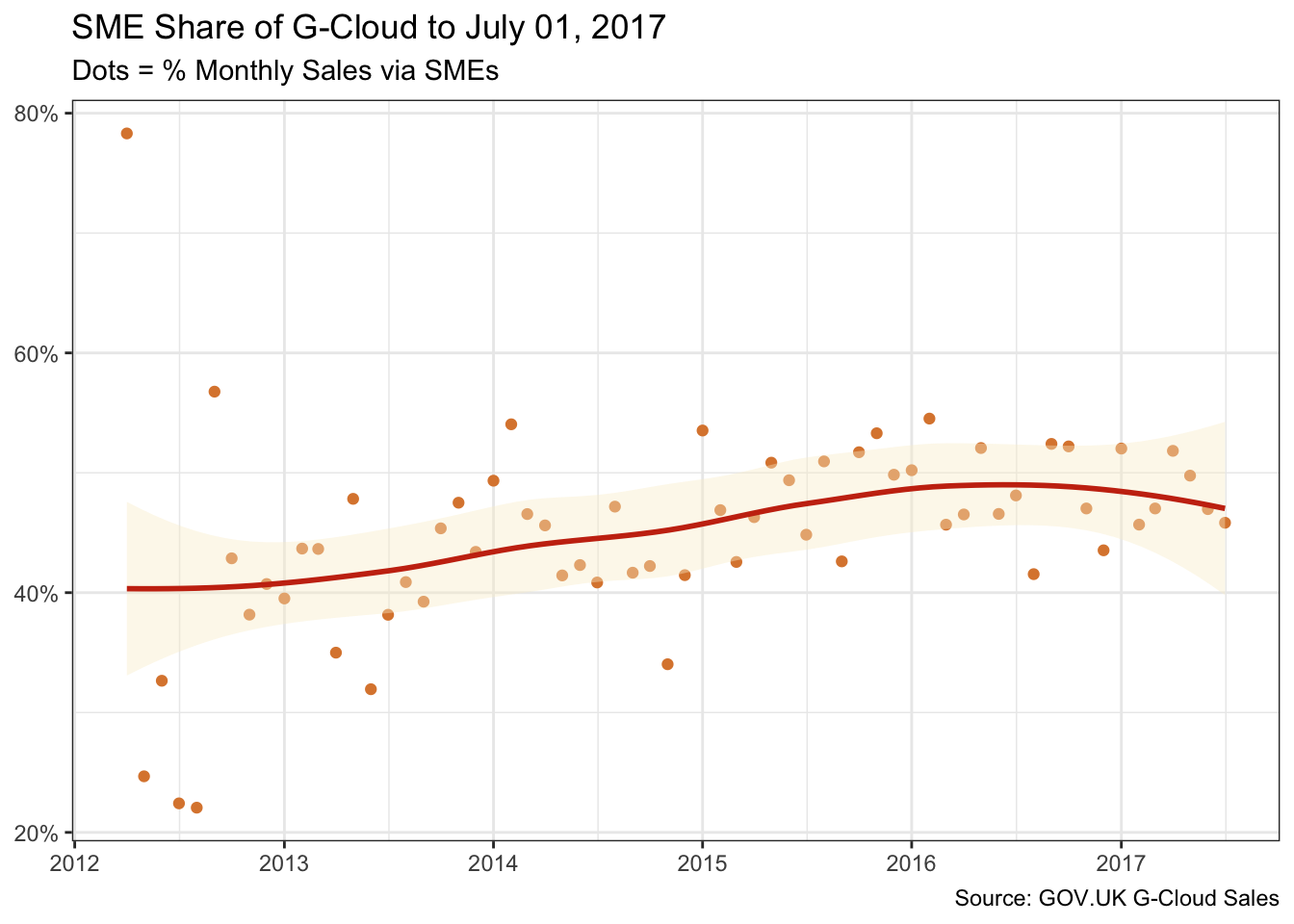
Sales grew steadily to a cumulative £2.4B by July 2017. And as the volume of sales grew, an increasingly clearer picture of sustained growth in the SME share emerged. However, in those latter few months, SMEs lost a little ground.
Dig a little deeper, and one can also see variation by sub-sector. And that’s after setting aside those buyers with cumulative G-Cloud spend below £100k, where large enterprise suppliers are less inclined to compete.
sector_df <- gcloud_df |>
mutate(sector = if_else(
sector %in% c("Central Government", "Local Government",
"Police", "Health"), sector, "Other Sector")
) |>
summarise(
evidenced_spend = sum(evidenced_spend, na.rm = TRUE),
sme_spend = sum(sme_spend, na.rm = TRUE),
pct = sme_spend / evidenced_spend,
.by = c(customer_name, sector)
) |>
filter(evidenced_spend >= 100000) |>
mutate(median_pct = median(pct), .by = sector) |>
mutate(sector = fct_reorder(sector, median_pct))
n_df <- sector_df |> summarise(n = n(), .by = sector)
sector_df |>
ggplot(aes(sector, pct)) +
geom_boxplot(outlier.shape = FALSE, fill = pal[3]) +
geom_jitter(width = 0.2, alpha = 0.5, colour = pal[2]) +
geom_label(aes(y = .75, label = glue("n = {n}")),
data = n_df,
fill = pal[1], colour = "white"
) +
scale_y_continuous(labels = label_percent()) +
labs(
x = NULL, y = NULL,
title = glue("SME Share of G-Cloud to {last_date}"),
subtitle = "% Sales via SMEs for Buyers with Cumulative Sales >= £100k",
caption = "Source: gov.uk G-Cloud Sales"
)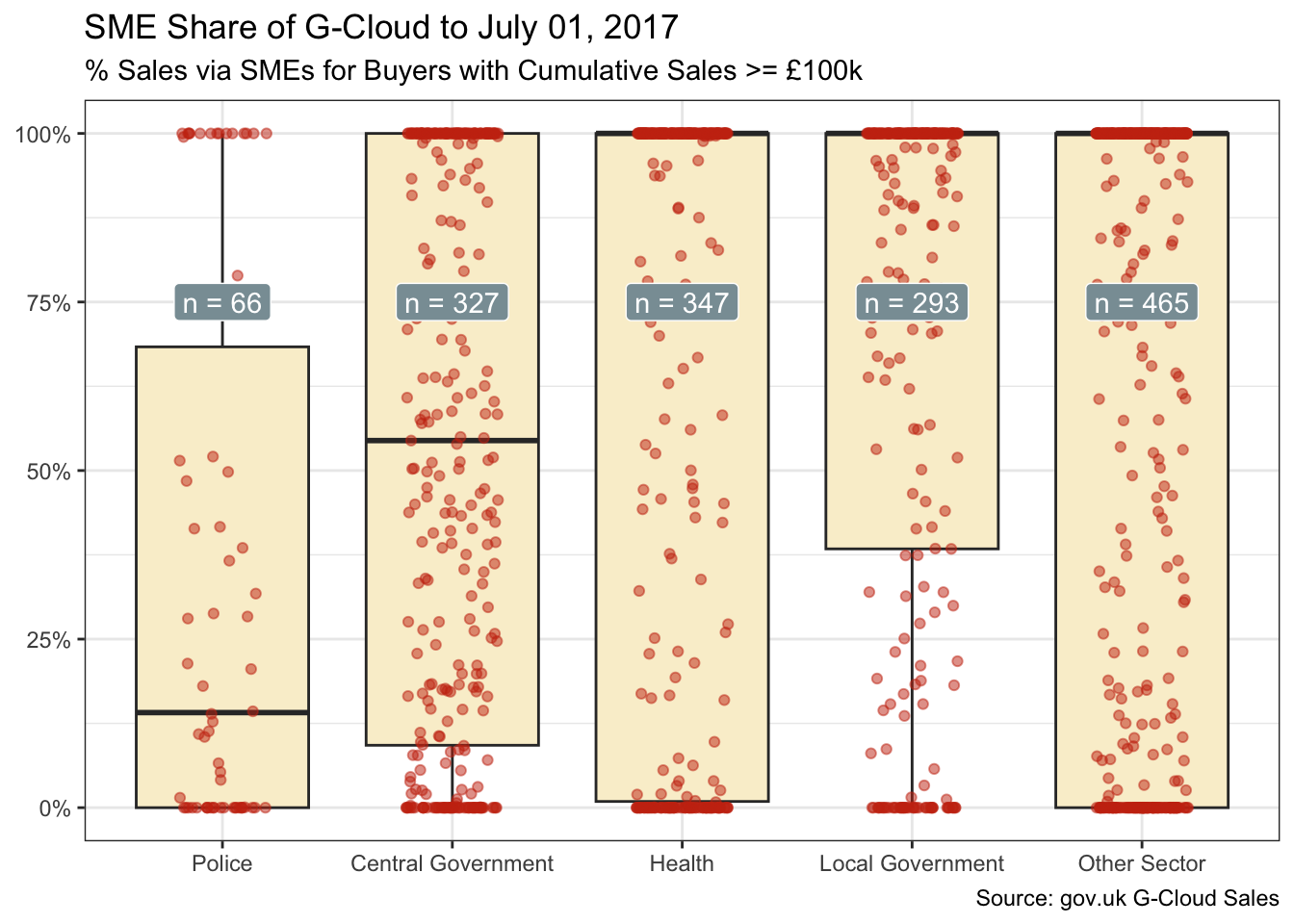
The box plot, overlaid with jittered points to avoid over-plotting, shows:
- Central government, with its big-spending departments, and police favouring large suppliers. This may reflect, among other things, their ability to scale.
- Local government and health, in contrast, favouring SMEs. And this despite their looser tether to central government strategy.
So, irrespective of whether service integration is taken in-house or handled by a service integrator, large enterprise suppliers have much to offer:
- The ability to deliver at scale;
- A breadth and depth of capabilities exploitable during discovery to better articulate the “art of the possible”;
- A re-assurance that there is always extensive capability on hand.
SMEs offer flexibility, fresh thinking and broader competition, often deploying their resources and building their mission around a narrower focus. They tend to do one thing, or a few things, exceptionally well.
These data are explored further in Six months later and Can Ravens Forecast.
R Toolbox
Summarising below the packages and functions used in this post enables me to separately create a toolbox visualisation summarising the usage of packages and functions across all posts.
| Package | Function |
|---|---|
| base | as.Date[1], as.numeric[1], c[2], is.na[1], library[9], max[1], sum[4] |
| clock | date_format[1] |
| conflicted | conflict_prefer_all[1], conflict_scout[1], conflicts_prefer[2] |
| dplyr | arrange[1], filter[1], if_else[4], mutate[4], n[1], pull[1], summarise[4] |
| forcats | fct_reorder[1] |
| ggfoundry | display_palette[1] |
| ggplot2 | aes[3], geom_boxplot[1], geom_jitter[1], geom_label[1], geom_point[1], geom_smooth[1], ggplot[2], labs[2], scale_x_date[1], scale_y_continuous[2], theme_bw[1], theme_set[1] |
| glue | glue[3] |
| janitor | clean_names[1] |
| lubridate | dmy[1] |
| paletteer | paletteer_d[1] |
| readr | parse_number[1], read_csv[1] |
| scales | label_percent[2] |
| stats | median[1] |
| stringr | str_c[1], str_remove_all[1] |
| usedthese | used_here[1] |
References
Wickham, Hadley, Mara Averick, Jennifer Bryan, Winston Chang, Lucy D’Agostino McGowan, Romain François, Garrett Grolemund, et al. 2019. “Welcome to the Tidyverse” 4: 1686. https://doi.org/10.21105/joss.01686.
Wickham, Hadley, Romain François, Lionel Henry, and Kirill Müller. 2022. “Dplyr: A Grammar of Data Manipulation.” https://CRAN.R-project.org/package=dplyr.
Wickham, Hadley, Jim Hester, and Jennifer Bryan. 2022. “Readr: Read Rectangular Text Data.” https://CRAN.R-project.org/package=readr.
Footnotes
Contains public sector information licensed under the Open Government Licence v3.0.↩︎