library(conflicted)
library(tidyverse)
conflict_prefer_all("dplyr", quiet = TRUE)
conflicts_prefer(tidyr::unite)
library(rvest)
library(furrr)
library(tictoc)
library(ggupset)
library(ggVennDiagram)
library(glue)
library(paletteer)
library(ggfoundry)
library(usedthese)
conflict_scout()
plan(multisession, workers = 10)Where Clouds Cross
R
sets
web scraping
regex
Visualising the dozens of overlapping sets formed by categories of cloud services

When visualising a small number of overlapping sets, Venn diagrams work well. But what if there are more. Here’s a tidyverse approach to the exploration of sets and their intersections.
In Let’s Jitter I looked at a relatively simple set of cloud-service-related sales data. G-Cloud data offers a much richer source with many thousands of services documented by several thousand suppliers and hosted across myriad web pages. These services straddle many categories. I’ll use these data to explore the sets and where they cross.
theme_set(theme_bw())
pal_name <- "wesanderson::Royal2"
pal <- paletteer_d(pal_name)
display_palette(pal, pal_name)
I’m going to focus on the Cloud Hosting lot. Suppliers document the services they want to offer to Public Sector buyers. Each supplier is free to assign each of their services to one or more service categories. It would be interesting to see how these categories overlap when looking at the aggregated data.
I’ll begin by harvesting the URL for each category’s search results. And I’ll also capture the number of search pages for each category. This will enable me to later control how R iterates through the web pages to extract the required data.
path <-
str_c("https://www.applytosupply.digitalmarketplace",
".service.gov.uk/g-cloud/search?lot=cloud-")
lot_urls <-
c(
str_c(path, "hosting"),
str_c(path, "software"),
str_c(path, "support")
)
cat_urls <- future_map(lot_urls, \(x) {
nodes <- x |>
read_html() |>
html_elements(".app-lot-filter__last-list li a")
tibble(
url = nodes |>
html_attr("href"),
pages = nodes |>
html_text()
)
}) |>
list_rbind() |>
mutate(
pages = parse_number(as.character(pages)),
pages = if_else(pages %% 30 > 0, pages %/% 30 + 1, pages %/% 30),
lot = str_extract(url, "(?<=cloud-)[\\w]+"),
url = str_remove(url, ".*(?=&)")
)
version <- lot_urls[[1]] |>
read_html() |>
html_elements(".app-search-result:first-child") |>
html_text() |>
str_extract("G-Cloud \\d\\d")So now I’m all set to parallel process through the data at two levels. At category level. And within each category, I’ll iterate through the multiple pages of search results, harvesting 100 service IDs per page.
I’ll also auto-abbreviate the category names so I’ll have the option of more concise names for less-cluttered plotting later on.
Tip
Hover over the numbered code annotation symbols for REGEX explanations.
tic()
data_df <-
pmap(cat_urls, \(url, pages, lot) {
cat("\n", url, " | ", pages, " | ", lot)
future_map(1:pages, possibly(\(pages) {
refs <- str_c(
"https://www.applytosupply.digitalmarketplace",
".service.gov.uk/g-cloud/search?page=",
pages, url, "&lot=cloud-", lot
) |>
read_html() |>
html_elements("#js-dm-live-search-results .govuk-link") |>
html_attr("href")
tibble(
lot = str_c("Cloud ", str_to_title(lot)),
service_id = str_extract(refs, "[[:digit:]]{15}"),
cat = str_remove(url, "&serviceCategories=") |>
str_replace_all("\\Q+\\E", " ") |>
str_remove("%28[[:print:]]+%29")
)
}), .progress = TRUE) |> bind_rows()
}
) |>
bind_rows() |>
select(lot:cat) |>
mutate(
cat = str_trim(cat) |> str_to_title(),
abbr = str_remove(cat, "and") |> abbreviate(3) |> str_to_upper()
) |>
drop_na(service_id)
toc()- 1
-
[[:digit:]]{15}finds the 15-digit service ID in the scraped link. - 2
-
\\Q+\\Efinds the literal+character rather than interpreting it as a one or more quantifier (i.e. if the\\Qand\\Ewere not specified)
&serviceCategories=archiving+backup+and+disaster+recovery | 42 | hosting
&serviceCategories=compute+and+application+hosting | 54 | hosting
&serviceCategories=container+service | 19 | hosting
&serviceCategories=content+delivery+network | 13 | hosting
&serviceCategories=data+warehousing | 16 | hosting
&serviceCategories=nosql+database | 13 | hosting
&serviceCategories=relational+database | 21 | hosting
&serviceCategories=other+database+services | 21 | hosting
&serviceCategories=distributed+denial+of+service+attack+%28ddos%29+protection | 16 | hosting
&serviceCategories=firewall | 26 | hosting
&serviceCategories=infrastructure+and+platform+security | 43 | hosting
&serviceCategories=intrusion+detection | 18 | hosting
&serviceCategories=load+balancing | 23 | hosting
&serviceCategories=logging+and+analysis | 25 | hosting
&serviceCategories=message+queuing+and+processing | 7 | hosting
&serviceCategories=networking+%28including+network+as+a+service%29 | 32 | hosting
&serviceCategories=platform+as+a+service+%28paas%29 | 59 | hosting
&serviceCategories=protective+monitoring | 23 | hosting
&serviceCategories=search | 10 | hosting
&serviceCategories=block+storage | 19 | hosting
&serviceCategories=object+storage | 17 | hosting
&serviceCategories=other+storage+services | 23 | hosting
&serviceCategories=accounting+and+finance | 99 | software
&serviceCategories=analytics+and+business+intelligence | 195 | software
&serviceCategories=application+security | 121 | software
&serviceCategories=collaborative+working | 231 | software
&serviceCategories=creative+design+and+publishing | 74 | software
&serviceCategories=customer+relationship+management+%28crm%29 | 128 | software
&serviceCategories=electronic+document+and+records+management+%28edrm%29 | 142 | software
&serviceCategories=healthcare | 68 | software
&serviceCategories=human+resources+and+employee+management | 118 | software
&serviceCategories=information+and+communications+technology+%28ict%29 | 322 | software
&serviceCategories=legal+and+enforcement | 42 | software
&serviceCategories=marketing | 89 | software
&serviceCategories=operations+management | 215 | software
&serviceCategories=project+management+and+planning | 98 | software
&serviceCategories=sales | 38 | software
&serviceCategories=schools+education+and+libraries | 48 | software
&serviceCategories=software+development+tools | 80 | software
&serviceCategories=transport+and+logistics | 40 | software
&serviceCategories=planning | 694 | support
&serviceCategories=setup+and+migration | 632 | support
&serviceCategories=quality+assurance+and+performance+testing | 556 | support
&serviceCategories=security+services | 514 | support
&serviceCategories=training | 576 | support
&serviceCategories=ongoing+support | 477 | support849.51 sec elapsedNow that I have a nice tidy tibble (Müller and Wickham 2022), I can start to think about visualisations.
I like Venn diagrams. But to create one I’ll first need to do a little prep as ggVennDiagram (Gao 2022) requires separate character vectors for each set.
host_df <- data_df |>
filter(lot == "Cloud Hosting") |>
group_by(abbr)
keys <- host_df |>
group_keys() |>
pull(abbr)
all_cats <- host_df |>
group_split() |>
map("service_id") |>
set_names(keys)Venn diagrams work best with a small number of sets. So we’ll select four categories.
four_cats <- all_cats[c("CAAH", "PAAS", "OBS", "IND")]
four_cats |>
ggVennDiagram(label = "count", label_alpha = 0) +
scale_fill_gradient(low = pal[5], high = pal[3]) +
scale_colour_manual(values = pal[c(rep(4, 4))]) +
labs(
x = "Category Combinations", y = NULL, fill = "# Services",
title = "The Most Frequent Category Combinations",
subtitle = glue("Focusing on Four {version} Service Categories"),
caption = "Source: digitalmarketplace.service.gov.uk\n"
)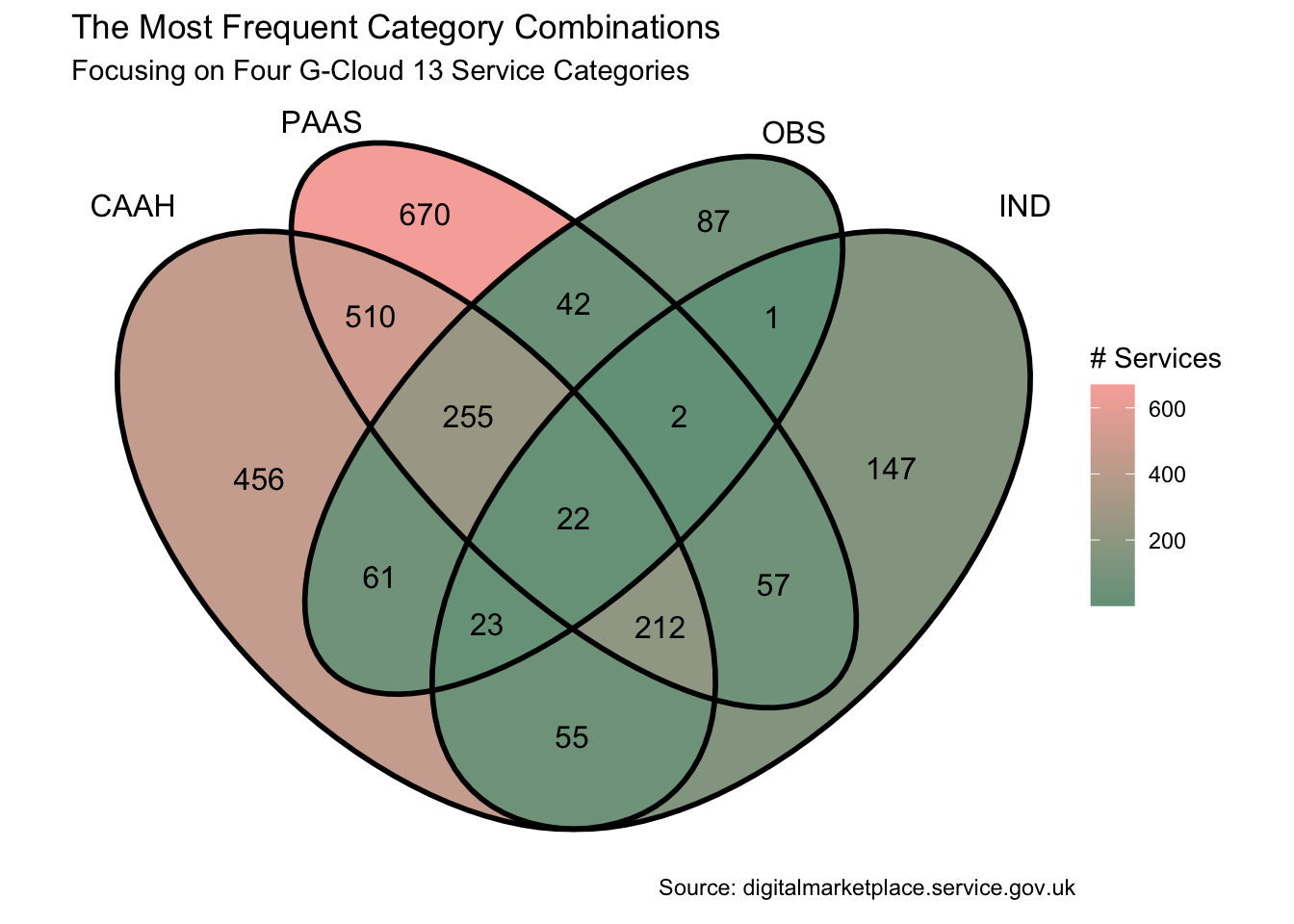
Let’s suppose I want to find out which Service IDs lie in a particular intersection. Perhaps I want to go back to the web site with those IDs to search for, and read up on, those particular services. I could use purrr’s reduce to achieve this. For example, let’s extract the IDs at the heart of the Venn which intersect all categories.
four_cats |> reduce(intersect) [1] "498337261767401" "735625897584273" "941404079421892" "468519278288161"
[5] "374608633231624" "528818827198493" "280215972809304" "590998313986731"
[9] "745846238180953" "173163384195854" "924318408511326" "567519735271974"
[13] "920078916328776" "507106315499984" "247181335014212" "760565690434196"
[17] "444063486713295" "567990943722560" "674396953847294" "546389562586229"
[21] "616594390875571" "720996025285364"And if we wanted the IDs intersecting the “OBS” and “IND” categories?
list(
four_cats$OBS,
four_cats$IND
) |>
reduce(intersect) [1] "498337261767401" "133496132306460" "622063745429810" "735625897584273"
[5] "282378513056803" "824432812764583" "941404079421892" "924245378460936"
[9] "468519278288161" "374608633231624" "757286918878249" "979714835327372"
[13] "528818827198493" "280215972809304" "361367891935175" "430661499045459"
[17] "590998313986731" "964621745018513" "745846238180953" "406334290207572"
[21] "173163384195854" "924318408511326" "226716894364641" "671131299650396"
[25] "567519735271974" "920078916328776" "507106315499984" "247181335014212"
[29] "760565690434196" "444063486713295" "567990943722560" "390438216681657"
[33] "263304084312287" "133984215794494" "674396953847294" "761608237467474"
[37] "426708477587492" "147659063793653" "473971905529841" "546389562586229"
[41] "616594390875571" "172104444338022" "492044345034335" "720996025285364"
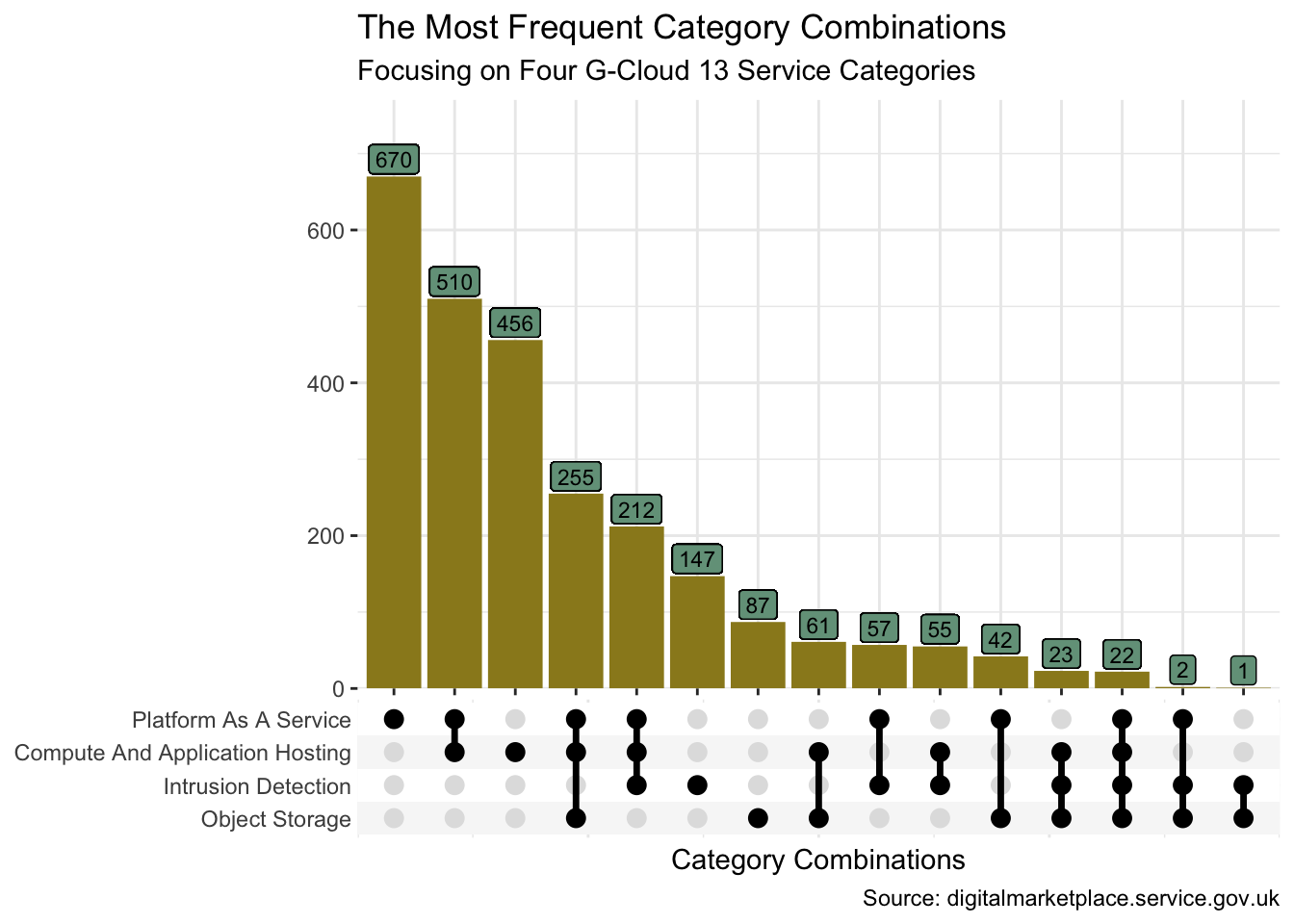
[45] "266583255948268" "420184478022971" "746066603748154" "455997758057773"Sometimes though we need something a little more scalable than a Venn diagram. The ggupset package provides a good solution. Before we try more than four sets though, I’ll first use the same four categories so we may compare the visualisation to the Venn.
set_df <- data_df |>
filter(abbr %in% c("CAAH", "PAAS", "OBS", "IND")) |>
mutate(category = list(cat), .by = service_id) |>
distinct(service_id, category) |>
mutate(n = n(), .by = category)
set_df |>
ggplot(aes(category)) +
geom_bar(fill = pal[1]) +
geom_label(aes(y = n, label = n), vjust = -0.1, size = 3, fill = pal[5]) +
scale_x_upset() +
scale_y_continuous(expand = expansion(mult = c(0, 0.15))) +
theme(panel.border = element_blank()) +
labs(
x = "Category Combinations", y = NULL,
title = "The Most Frequent Category Combinations",
subtitle = glue("Focusing on Four {version} Service Categories"),
caption = "Source: digitalmarketplace.service.gov.uk"
)
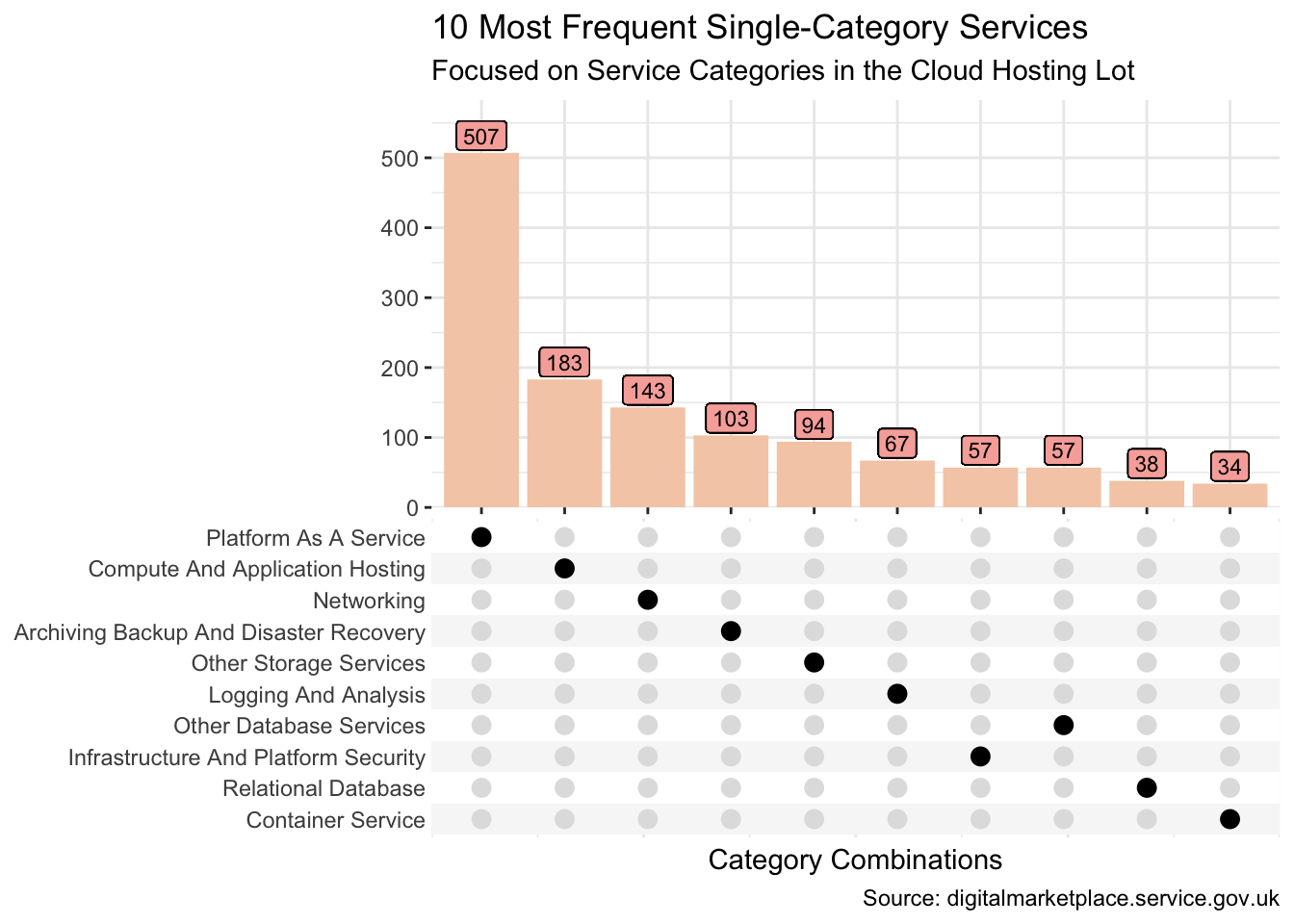
Now let’s take a look at the intersections across all the categories. And let’s suppose that our particular interest is all services which appear in one, and only one, category.
set_df <- data_df |>
filter(n() == 1, lot == "Cloud Hosting", .by = service_id) |>
mutate(category = list(cat), .by = service_id) |>
distinct(service_id, category) |>
mutate(n = n(), .by = category)
set_df |>
ggplot(aes(category)) +
geom_bar(fill = pal[2]) +
geom_label(aes(y = n, label = n), vjust = -0.1, size = 3, fill = pal[3]) +
scale_x_upset(n_sets = 10) +
scale_y_continuous(expand = expansion(mult = c(0, 0.15))) +
theme(panel.border = element_blank()) +
labs(
x = "Category Combinations", y = NULL,
title = "10 Most Frequent Single-Category Services",
subtitle = "Focused on Service Categories in the Cloud Hosting Lot",
caption = "Source: digitalmarketplace.service.gov.uk"
)
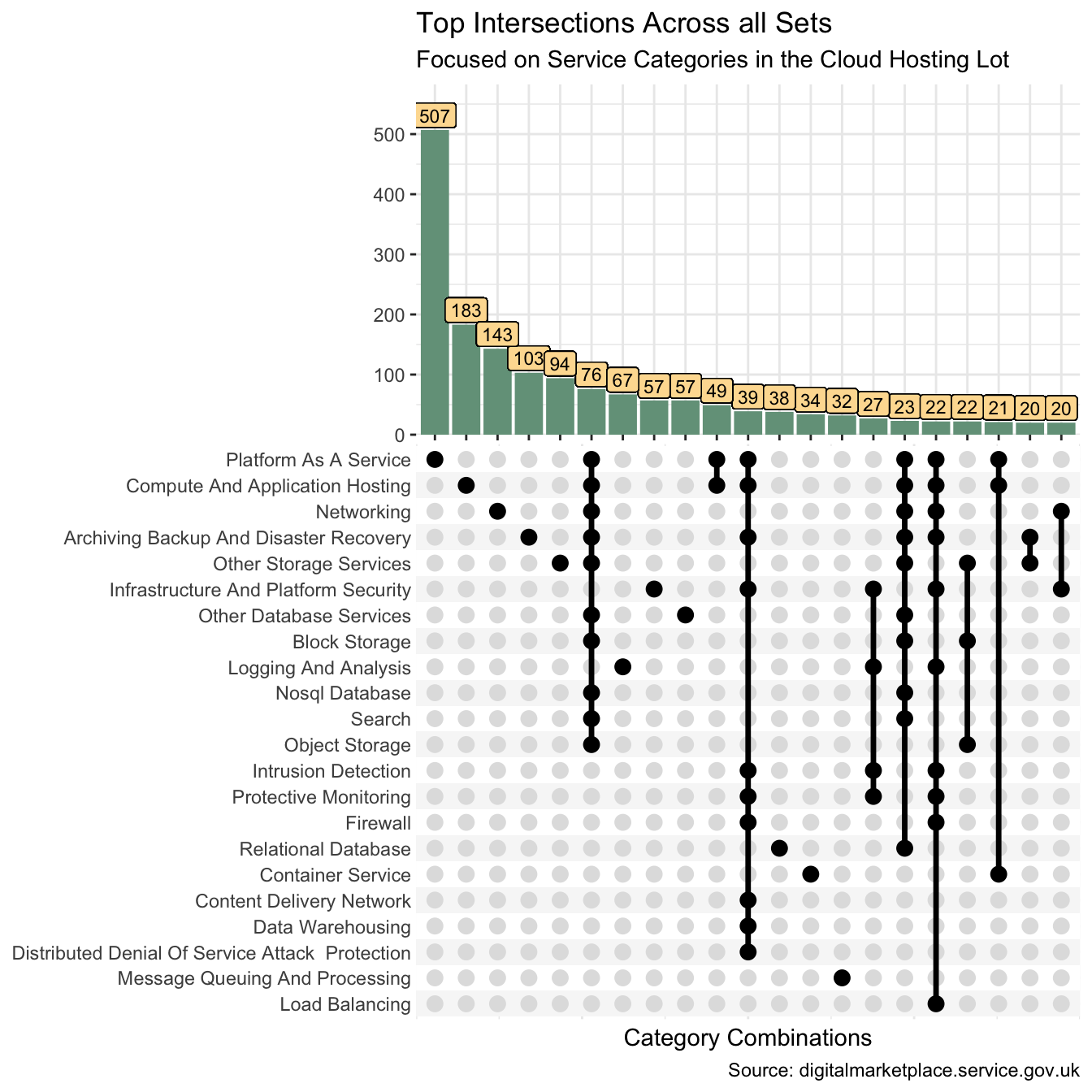
Suppose we want to extract the intersection data for the top intersections across all sets. I could use functions from the tidyr package to achieve this.
cat_mix <- data_df |>
filter(lot == "Cloud Hosting") |>
mutate(x = cat) |>
pivot_wider(service_id, names_from = cat, values_from = x, values_fill = "^") |>
unite(col = intersect, -service_id, sep = "/") |>
count(intersect) |>
mutate(
intersect = str_replace_all(intersect, "(?:\\Q/^\\E|\\Q^/\\E)", ""),
intersect = str_replace_all(intersect, "/", " | ")
) |>
arrange(desc(n)) |>
slice(1:21)
cat_mix |>
rename(
"Intersecting Categories" = intersect,
"Services Count" = n
)| Intersecting Categories | Services Count |
|---|---|
| Platform As A Service | 507 |
| Compute And Application Hosting | 183 |
| Networking | 143 |
| Archiving Backup And Disaster Recovery | 103 |
| Other Storage Services | 94 |
| Archiving Backup And Disaster Recovery | Compute And Application Hosting | Nosql Database | Other Database Services | Networking | Platform As A Service | Search | Block Storage | Object Storage | Other Storage Services | 76 |
| Logging And Analysis | 67 |
| Other Database Services | 57 |
| Infrastructure And Platform Security | 57 |
| Compute And Application Hosting | Platform As A Service | 49 |
| Archiving Backup And Disaster Recovery | Compute And Application Hosting | Content Delivery Network | Data Warehousing | Distributed Denial Of Service Attack Protection | Firewall | Infrastructure And Platform Security | Intrusion Detection | Platform As A Service | Protective Monitoring | 39 |
| Relational Database | 38 |
| Container Service | 34 |
| Message Queuing And Processing | 32 |
| Infrastructure And Platform Security | Intrusion Detection | Logging And Analysis | Protective Monitoring | 27 |
| Archiving Backup And Disaster Recovery | Compute And Application Hosting | Nosql Database | Relational Database | Other Database Services | Networking | Platform As A Service | Search | Block Storage | Other Storage Services | 23 |
| Archiving Backup And Disaster Recovery | Compute And Application Hosting | Firewall | Infrastructure And Platform Security | Intrusion Detection | Load Balancing | Logging And Analysis | Networking | Platform As A Service | Protective Monitoring | 22 |
| Block Storage | Object Storage | Other Storage Services | 22 |
| Compute And Application Hosting | Container Service | Platform As A Service | 21 |
| Archiving Backup And Disaster Recovery | Other Storage Services | 20 |
| Infrastructure And Platform Security | Networking | 20 |
And I can compare this table to the equivalent ggupset (Ahlmann-Eltze 2020)visualisation.
set_df <- data_df |>
filter(lot == "Cloud Hosting") |>
mutate(category = list(cat), .by = service_id) |>
distinct(service_id, category) |>
mutate(n = n(), .by = category)
set_df |>
ggplot(aes(category)) +
geom_bar(fill = pal[5]) +
geom_label(aes(y = n, label = n), vjust = -0.1, size = 3, fill = pal[4]) +
scale_x_upset(n_sets = 22, n_intersections = 21) +
scale_y_continuous(expand = expansion(mult = c(0, 0.15))) +
theme(panel.border = element_blank()) +
labs(
x = "Category Combinations", y = NULL,
title = "Top Intersections Across all Sets",
subtitle = "Focused on Service Categories in the Cloud Hosting Lot",
caption = "Source: digitalmarketplace.service.gov.uk"
)
And if I want to extract all the service IDs for the top 5 intersections, I could use dplyr (Wickham et al. 2022) and tidyr (Wickham and Girlich 2022) verbs to achieve this too.
I won’t print them all out though!
top5_int <- data_df |>
filter(lot == "Cloud Hosting") |>
select(service_id, abbr) |>
mutate(x = abbr) |>
pivot_wider(names_from = abbr, values_from = x, values_fill = "^") |>
unite(col = intersect, -service_id, sep = "/") |>
mutate(
intersect = str_replace_all(intersect, "(?:\\Q/^\\E|\\Q^/\\E)", ""),
intersect = str_replace(intersect, "/", " | ")
) |>
mutate(count = n_distinct(service_id), .by = intersect) |>
arrange(desc(count), intersect, service_id) |>
add_count(intersect, wt = count, name = "temp") |>
mutate(temp = dense_rank(desc(temp))) |>
filter(temp %in% 1:5) |>
distinct(service_id)
top5_int |>
summarise(service_ids = n_distinct(service_id))| service_ids |
|---|
| 1030 |
R Toolbox
Summarising below the packages and functions used in this post enables me to separately create a toolbox visualisation summarising the usage of packages and functions across all posts.
used_here()| Package | Function |
|---|---|
| base | abbreviate[1], as.character[1], c[7], cat[1], library[11], list[4], rep[1] |
| conflicted | conflict_prefer_all[1], conflict_scout[1], conflicts_prefer[1] |
| dplyr | add_count[1], arrange[2], bind_rows[2], count[1], dense_rank[1], desc[3], distinct[4], filter[7], group_by[1], group_keys[1], group_split[1], if_else[1], mutate[14], n[4], n_distinct[2], pull[1], rename[1], select[2], slice[1], summarise[1] |
| furrr | future_map[2] |
| future | plan[1] |
| ggVennDiagram | ggVennDiagram[1] |
| ggfoundry | display_palette[1] |
| ggplot2 | aes[6], element_blank[3], expansion[3], geom_bar[3], geom_label[3], ggplot[3], labs[4], scale_colour_manual[1], scale_fill_gradient[1], scale_y_continuous[3], theme[3], theme_bw[1], theme_set[1] |
| ggupset | scale_x_upset[3] |
| glue | glue[2] |
| paletteer | paletteer_d[1] |
| purrr | list_rbind[1], map[1], pmap[1], possibly[1], reduce[2] |
| readr | parse_number[1] |
| rlang | set_names[1] |
| rvest | html_attr[2], html_elements[3], html_text[2] |
| stringr | str_c[6], str_extract[3], str_remove[4], str_replace[1], str_replace_all[4], str_to_title[2], str_to_upper[1], str_trim[1] |
| tibble | tibble[2] |
| tictoc | tic[1], toc[1] |
| tidyr | drop_na[1], pivot_wider[2], unite[2] |
| usedthese | used_here[1] |
| xml2 | read_html[3] |
References
Ahlmann-Eltze, Constantin. 2020. “Ggupset: Combination Matrix Axis for ’Ggplot2’ to Create ’UpSet’ Plots.” https://CRAN.R-project.org/package=ggupset.
Gao, Chun-Hui. 2022. “ggVennDiagram: A ’Ggplot2’ Implement of Venn Diagram.” https://CRAN.R-project.org/package=ggVennDiagram.
Müller, Kirill, and Hadley Wickham. 2022. “Tibble: Simple Data Frames.” https://CRAN.R-project.org/package=tibble.
Wickham, Hadley, Romain François, Lionel Henry, and Kirill Müller. 2022. “Dplyr: A Grammar of Data Manipulation.” https://CRAN.R-project.org/package=dplyr.
Wickham, Hadley, and Maximilian Girlich. 2022. “Tidyr: Tidy Messy Data.” https://CRAN.R-project.org/package=tidyr.